How To Traverse XML
To begin this article, we take a look at how to make the transformations dangled in front of you throughout the last article actually occur on your own local machine. This should give you a "virtual playground" where you can experiment with all the various XSL and XSLT constructs on your own, as well as adding more complex formatting to the stylesheet we created last article. It mwill also begin our closer look into how an XSLT processor works. We then complement our view of a processor's output with a detailed look at the type of input it expects, and the format of this input. This leads us into a first look at the Document Object Model (DOM), an alternative to using SAX for getting to XML data. Finally, we will begin to move back a step from parsers, processors, and APIs, and look at how to put an XML application together. This will set the tone for the rest of the book, as we take a more topical approach on various types of XML applications and how to take advantage of proven design patterns and XML frameworks. Before going on, you should understand not only the focus of the article, but also what it does not focus on. This article will not teach you how to write an XSLT processor, any more than previous articles taught you to write an XML parser. Certainly the concepts here are very important, in fact critical, to using an XSLT processor, and are a great starting point for getting involved with existing efforts to enhance XSLT = processors, such as the Apache Group's Xalan processor. However, parsers and processors are extremely complex programs, and to try to explain the inner workings of them within these pages would consume the rest of this book and possibly another! Instead, we continue to take the approach of an application developer or Java architect; we use the excellent tools that are available, and enhance them when needed. In other words, you have to start somewhere, and for a Java developer, using a processor should precede trying to code one.
Getting the Output
If you followed along with our examples in the last article, you should be ready to put your stylesheet and XML document through a processor and see the output for yourself. This is a fairly straightforward process with most XSLT processors. Continuing in our vein of using open source, best-of-breed products, we will use the Apache Xalan XSLT processor, which you can find information. In addition to being contributed to by Lotus, IBM, Sun, Oracle, and some of the best open source minds in the business, Xalan fits in very well with Apache Xerces, the parser we looked at in earlier articles. If you already have another processor, you should easily be able to find the programs and instructions needed to run the examples in this article; your output should also be identical or very close to the example output we look at here.
The first use of an XSLT processor we will investigate is invoking it from a command line. This is often done for debugging, testing, and offline development of content. Consider that many highperformance web sites generate their content offline, often nightly or weekly, to reduce the load and performance constraints of dynamically transforming XML into HTML or other markup languages when a user requests a page. We can also use this as a starting point for peeling back the layers of an XML transformation. Consult your processor's documentation for how to use XSLT from the command line. For Apache Xalan, the command used to perform this task is:
D:\prod\JavaXML> java org.apache.xalan.xslt.Process
-IN [XML Document]
-XSL [XSL Stylesheet]
-OUT [Output Filename]
Xalan, like any processor you choose, can take in many other command-line options, but these three are the primary ones we want to use. Xalan also uses the Xerces parser by default, so you will need to have both the parser and processor classes in your class path to run Xalan from the command line. You can specify a different XML parser implementation through the command line if you wish, although the support for Xerces is more advanced than for other parsers. You also do not need to reference a stylesheet in your XML document if generating a transformation this way; the XSLT processor will apply the stylesheet you specify on the command line to the XML document. We will use our XML document's internal stylesheet declarations. So taking the names of our XML document and XSL stylesheet (in this case in a subdirectory), we can determine the syntax needed to run the processor. Since we are transforming our XML into HTML, we specify contents.html as the output for the transformation:
D:\prod\JavaXML> java org.apache.xalan.xslt.Process
-IN contents.xml
-XSL XSL/JavaXML.html.xsl
-OUT contents.html
Running this command from the appropriate directory should cause Xalan to begin the transformation process, giving you output similar to that shown in Example (a).
Example (a) . Transforming XML with Apache Xalan
D:\prod\JavaXML>java org.apache.xalan.xslt.Process
-IN contents.xml
-XSL XSL/JavaXML.html.xsl
-OUT contents.html
========= Parsing file:D:/prod/JavaXML/XSL/JavaXML.html.xsl ==========
Parse of file:D:/prod/JavaXML/XSL/JavaXML.html.xsl took 1161 milliseconds
========= Parsing contents.xml ==========
Parse of contents.xml took 311 milliseconds
=============================
Transforming...
transform took 300 milliseconds
XSLProcessor: done
Once this is complete, you should be able to open the generated file, contents.html, in an editor or web browser. If you followed along with all the examples in the last article, your HTML document should look similar to Figure (b).
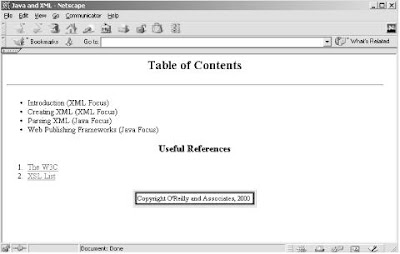
Figure(b) . HTML from XML transformation
As simple as that, you have a means to make changes and test the resultant output from XML and XSL stylesheets! The Xalan processor, when run from the command line, also has the helpful feature of identifying errors that may occur in your XML or XSL and the line numbers on which those errors are encountered in the source documents, aiding even further in testing and debugging.
Getting the Input
Besides the reasons already mentioned for not going into how a processor works, there is an even better reason not to spend time on the issue: the inputs and outputs of the processor are far more interesting! You have seen how to parse a document incrementally with the SAX interfaces and classes. You can easily make decisions within the process about what to do with the elements encountered, how to handle particular attributes, and what actions error conditions should result in. However, there are some problems with using that model in various situations, and providing input to an XSLT processor is one of them.
SAX Is Sequential
The sequential model that SAX provides does not allow for random access to an XML document. In other words, in SAX you get information about the XML document as the parser does, and lose that information when the parser does. When element 2 comes along, it cannot access information in element 4, because element 4 hasn't been parsed yet. When element 4 comes along, it can't "look back" on element 2. Certainly, you have every right to save the information encountered as the process moves along; coding all these special cases can be very tricky, though. The other more extreme option is to build an in-memory representation of the XML document. We will see in a moment that a Document Object Model parser does exactly that for us, so performing the same task in SAX would be pointless, and probably slower and more difficult.
SAX Siblings
Another difficult task to achieve with the SAX model is moving laterally between elements. The access provided in SAX is largely hierarchical, as well as sequential. You are going to reach leaf nodes of the first element, then move back up the tree, then down again to leaf nodes of the second element, and so on. At no point is there any clear relation of what "level" of the hierarchy you are at. Although this can be implemented with some clever counters, it is not what SAX is designed for. There is no concept of a sibling element; no concept of the next element at the same level, or of which elements are nested within which other elements. The problem with this lack of information is that an XSLT processor must be able to determine the siblings of an element, and more importantly, the children of an element. Here, templates are being applied via the xsl:apply-templates construct, but they are being applied to a specific node set that matches the given XPath expression. In this example, the template should be applied only to the elements myChildElement1 or myChildElement2 (separated by the XPath OR operator, the pipe). In addition, because a relative path is used, these must be direct children of the element myParentElement. Determining and locating these nodes with a SAX representation of an XML document would be extremely difficult. With an in-memory, hierarchical representation of the XML document, locating these nodes is trivial, another reason why the DO approach is heavily used for input into XSLT processors.
Why Use SAX At All?
All these discussions about the "shortcomings" of SAX may have you wondering why one would ever choose to use SAX at all. If you are thinking along these lines, remind yourself that these shortcomings are all in regard to a specific application of XML data, in this case processing it through XSL. In fact, all of these "problems" with using SAX are the exact reason you would choose to use SAX. Confusing? Maybe not as much as you think. Imagine parsing a table of contents represented in XML for an issue of National Geographic. This document could easily be 500 lines in length, more if there is a lot of content within the issue. Imagine an XML index for an O'Reilly book. Hundreds of words, with page numbers, crossreferences, and more. And these are all fairly small, concise applications of XML. As an XML document grows in size, so does the in-memory representation when represented by a DOM tree. Imagine an XML document so large and with so many nestings that the representation of it using the DOM begins to affect the performance of your application. And now imagine that the same results could be obtained by parsing the same input document sequentially using SAX, and only need one-tenth, or one-hundredth, of your system's resources to accomplish the task. The point of this example is that just as in Java there are many ways to do the same job, there are many ways to obtain the data in an XML document. In various scenarios, SAX is easily the better choice for quick, less-intensive parsing and processing. In other cases, the DOM provides an easyto- use, clean interface to data in a desirable format. You, the developer, must always analyze your application and its purpose to make the correct decision as to which method to use, or how to use both in concert. As always, the power to make good or bad decisions lies in your knowledge of the alternatives. Keeping that in mind, let's look at this new alternative in more detail.