DATA STRUCTURE
Introduction
In our daily life, we make so many programs, such as make a program to go to cinema, make a program to buy a scooter or make a program to have a dinner at Taj etc. Let us understand the concept of making a program by taking a simple example. If somebody tells you that make a program to buy some household items then what will you do? You would naturally follow some steps in order as:
- Firstly you will make a list of items and quantity of each item.
- Then you will collect the money for the house holds items.
- After this you will take a vehicle and go to market.
- In the market you will look for daily needs shop.
- After finding that particular shop, you hand over the list of items to the shopkeeper.
- The shopkeeper collects the items and gives the bill to you.
- You will clear the bill, and come back to home.
You do these steps on conscious level initially but after some time it is done on an unconscious level and it is an essential part of our daily life. Fortunately it is not necessary for you to consciously think of every step involved in a process as turning of this page by hand much of what we do unconsciously we once had to learn. For example we were taught to take a bath by taking the water into a tub, take bath soap in your hand and rub the soap against your body to clean your skin. After some time the action is completely automatic.
Every task in this real world is accomplished by following a logical sequence of steps. This logical sequence of steps is known as a program. And when we write these steps in any computer language it becomes a computer program. Therefore a sequence of instruction written in a computer language to be performed by a computer is known as a computer program. And the process of writing a sequence of instruction for a computer to follow is known as computer programming. From now on, when we will use the words program and programming, that means we are talking about computer program and computer programming.
Programming Style
It is not a better idea to write a program in any order. The program may work even if we write it in any order but it may look very odd. So it is necessary to have a specific order of our program. Now we will see some important consideration that should be kept in mind when we write a program.
Names of Data/Subprogram
The first and the most notable point is about the names, that we associate with the data and the subprograms. The names should be meaningful so that their appearances in the program can be easily recognized and appreciated. The names of each variable and each subprogram represent what they are doing in the program. If the names are suitable then it is easier to understand the working of a program by understanding its documentation. The concept of documentation would be clear later on.
Although there is no hard and fast rule that the name of this type of variable should be this one, but for a good programming style we should take some following tips:
- The names for subprograms, constants and all variables, local or global, should be given with special care so as to identify their meanings clearly and succinctly.
- The names of subprograms, constants and all variables, local or global, should be simple. For example if you are using a for loop then a single letter is often a good choice for the count controlled variable, but would be a poor choice for a subprogram.
- Always use common prefixes or suffixes to give names for subprograms belong to the same general category. For example, if we write subprograms for reading a matrix, displaying a matrix, addition of two matrixes, subtraction of two matrixes, and multiplication of two matrixes then we might use following names to these subprograms:
- Read_Matrix,
- Write_Matrix,
- Add_Matrix,Sub_Matrix,
- Mult_Matrix,
- Try to choose such names that are not close to each other in spelling or otherwise be ready to confuse.
- Avoid choosing such names that are little or nothing to do with the problem.
- Avoid deliberate misspelling and meaningless suffixes to obtain different names. Of all the names
Counter
Ounter
Counterr
Counter1
Counter2
only the first name should normally be used.
Another important aspect of a good programming ability is that one must also go through a certain procedure before writing a program. This procedure is composed of a problem solving phase and an implementation phase.
Problem Solving Phase
Analyze Problem Definition - It is the programmer who analyzes a problem definition, because computer can not do anything on its behalf. If the programmer thinks that the problem is very large and complex then he may divide the workload into smaller problems until they become easily manageable. And it is the programmer who decides exactly how to divide the work into subprograms, where each subprogram is intended to do only one task. So the programmer must be clear in its problem definition, after this the programmer must arrive at the solution and communicate it to the computer
General Solution - After analyzing the problem, the programmer develops a general solution called an algorithm. An algorithm is just a written description of a logical sequence of actions. Now let us write a precise definition of an algorithm. An algorithm is a finite set of instructions, which if followed step by step, accomplish a specific task in a finite amount of time for all possible conditions. There may be more than one solution for a problem and it is the programmer who selects the better one among the good ones.
Testing the algorithm - After developing a general solution, the programmer “walk through” the algorithm by performing each step mentally or manually. If this testing of algorithm does not produce the expected output, the programmer repeats the problem – solving phase and coming up with another algorithm, if required. When the programmer is satisfied with the algorithm only then it jumps to implementation phase.
Specific Solution - And when a programmer satisfies with its algorithm only then he might translate his algorithm into a programming language, such as Pascal, C, C++, FORTRAN, BASIC etc. And like other regional languages, such as English, French, Hindi etc., each programming language has its own symbols, special words and set of rules that are used to constitute a program. The programming language C has some rich features that make it the most appropriate choice to express the algorithms we develop. The translation of an algorithm into a computer program is called as coding the algorithm.
Testing The Program - The program is tested by running (executing) it on the computer system. If the programmer fails to produce the expected output, due to some error, the programmer should make the appropriate changes until it produces the expected output. The difficulty of finding errors increases much faster than its size. It means that if one program is twice the size of another program, then it may take even thrice or even four times as long. The combination of coding and testing an algorithm is often referred as implementing an algorithm.
Use the Program - After getting the expected output, the programmer can use this program according to his needs.
Documentation
Documentation is the written text and comments that makes a program easier for others to understand, use and modify. For a small program it is not so necessary to have a detailed documentation, because one can keep all details in one’s mind and so needs documentation only to explain the programmer to someone else. But if we write large programs then it is essential to have a detailed document because it is very difficult to keep all details in mind. And it is a good habit to prepare a document before starting to write a program or after writing a program.
Now we will see some guidelines that are commonly accepted while writing a good documentation:
When you start to write document for a subprogram, always place a prologue at the beginning of each subprogram that may include:
- Identity of the subprogram.
- Statement of the purpose of the subprogram and method used.
- The changes of the subprogram make and the date it uses.
- Reference, if any, to further document external to the program
Use meaningful names for variables. For example
area = 3.14 * radius * radius;
should be used to implement the formula
area = ∏r2
for finding the area of a circle.
- Wherever you use a variable or constant just explain what it is and how it is used.
- Use a comment while using each subprogram so that its purpose might be cleared.
- Indicate the end point of each subprogram if it is not otherwise obvious.
- It is not necessary to always use a comment for a statement which is itself explanatory, such as:
Counter = Counter * 5 /* Multiply Counter by 5 */
- If you have any statement that is unclear then explain it.
- The source code itself should explain how the program works and the documentation should explain why it works and what it does.
- Sooner or later whenever you make a change in your source code, be sure that the documentation is correspondingly modified. This is known as maintenance.
The clarity of the documentation comes by using spaces, blank lines, and identation. Their main purpose is that they made the program easy to read, allow us to tell at a glance which parts of the program relate to each other in a convenient way. It also tells where the major breaks occur and which statements are within loop body and which are not.
While writing a documentation, one should keep in mind that the documentation should be concise and descriptive. And a program without proper documentation soon becomes unusable.
Program Testing and Debugging
The process of detecting and removing errors in a program is referred as program testing and debugging. When we code the algorithm then it is not necessary that our program should be 100 percent error – free. It means that there may occur some errors in the program. & it is totally programmer’s duty to detect, isolate and correct any errors that are likely to be present in the program.
Generally there are four types of errors:
1. Syntax errors
2. Run – time errors
3. Logical errors
4. Latent errors
Syntax Errors
Like any ordinary language, C language has its own set of rules and the errors, which violate such rules, are referred as syntax errors. Syntax errors are immediately detected and isolated by the compiler during compilation purpose. Remember that the compilation phase of the program would not be completed until any syntax error is present in the program.
Following are the example of some syntax errors:
(i) int 1area, 1radius; /* starts with a number */
(ii) float $salary; /* starts with a dollar ($) sign */
(iii) char @basic /* starts with a @ sign */
Normally the compiler indicates the line number that has some error. But in some cases, the line number may not exactly indicate the place of error.
Run – Time Errors
The errors, which occur during the execution of a program, are referred as run – time errors or execution – time errors. Generally run – time errors come when there is any mismatch of basic data types or make a reference of an array element that falls outside its range, and so on. It means that if we have an array of 100 elements and we want to refer 103rd element or say 120th element then the compiler would compile the program successfully without detecting such errors. In this case the compiler produces erroneous results. Therefore it is the programmer who detects and isolates run – time errors.
Logical Errors
The errors, which are related to the logic of the program, are referred as logical errors. Such type of errors occurs due to wrong jumping, failure to satisfy a particular condition, and any incorrect order of evaluation of statements. Like run – time errors, the logical errors are not recognized by the compiler, otherwise they may produce wrong results.
Following are the examples of some logical errors:
(i) while (i=1)
{
stat1;
stat2;
------;
------;
}
here instead of using logical equal to (==) operator we have used assignment operator. A test like this might create infinite loop, because after each iteration 1 is assigned to I and the loops continues again and again.
(ii) if (a==b)
printf (“Both are equal”);
If a and b are float types values, then it is not necessary to become equal due to truncation error. Generally such type of errors occur due to incorrect coding of the algorithm.
Latent Errors
The errors, which occur due to the special values of data, are known as latent errors. Consider the following statements:
(i) y = 1 / x;
In this statement an error occurs only when x is equal to 0.
(ii) z = 4 / (x-y);
Here an error occurs when x and y are equal. Latent errors can be detected only by using all possible combination of test data.
Program Testing
Program testing is the process of running the program on sample data chosen to find errors, if they are present. From the earlier discussion of errors it is clear that the compiler can detect only the syntactic and semantics errors. All the remaining errors can be detected at run time only. Therefore it is necessary for the programmers to detect all such errors.
One of the most effective way to find errors is called a structured walkthrough. In other words we can call it as human testing. In this the programmer shows the complete source code to another programmer or a peer group. Structured walkthrough is carried out statement by statement and is analyzed with respect to a checklist of common errors. Such type of program testing is helpful for three reasons:
- The source code becomes familiar to the other programmers who can often find out errors that are overlooked by the original programmer.
- The questions asked by other programmer can clarify original programmer’s thinking and discover his own mistakes.
- The source code can be easily maintained in later stages of software development.
Now we will discuss about the choice of data to be used to test programs and subprograms. The choice of data depends on the type of environment the program (project) is intended to run. Here the important thing is about the quality of data rather than its quantity.
Basically there are two general testing methods.
- The Unit Test method – In this the program testing is done at subprogram level, where a subprogram is designed to perform only one task.
- An Integration Test method – After testing of all subprograms, the data should be tested according to the specification of the complete program, without regard to the internal details of the program. Such type of testing is made to find out the interfacing problems between different subprograms.
When we talk about the program testing, it is also necessary to point out the quality of test data. The quality of test data should be selected in the following ways:
- Easy values – The program is tested with data that are easy to check. For the newer one, the complicated data may embarrass him.
- Typical Realistic value – It is necessary to always try a program to be tested on simple realistic data so that the result can be checked by hand.
- Extreme values – One should always test one’s program at the limits of his range of application. It is very easy for counters or array bounds to be off by one.
- Illegal values – The program should be tested for some illegal values so that it becomes able to produce a sensible error message.
While testing your program, it should be remember that program testing can be used to show the presence of errors but never their absence.
Program Debugging
Program debugging is the process of isolating and correcting the errors. Usually a large program does not run correctly when it is executed as a whole the first time. If it has some errors then it is necessary to determine exactly where the errors are.
One simple and effective debugging tool is to take snapshots of program execution by inserting printf () statement at key points in main program. Once the location of an error is identified and the error is corrected, then these debugging (printf())statements may be removed from the program.
Another term, which is used to debug the program, is scaffolding. In scaffolding, we insert the comments in the source code. So whenever we write programs we place scaffolding into our programs; it will be easy to delete once it is no longer needed. In C language we have just one type of comment statement /* …… */.
The third error locating method is to backtrack the incorrect results through the logic of the program until the error is identified. This method is easy to locate errors in small programs. But for large programs, we may employ debugging tools, such as static analyzer, that examines the source program looking for uninitialized or unused variables, section of code that can never be reached, and other possible occurrences that are probably incorrect.
Data types, Data Objects and Data Structure
Almost every program, when run on the computer system, is intended to receive some raw data as its input and produces some refined data as its logical output. In other words, you can say, it is the data that interfaces between you and your program. That’s why very often we call our computer system as data processing system. Therefore the data is the information that has been put into a form usable by a computer. Our program operates on this data and produces the expected output. The data, which we use, may be of different types.
A data type is a term, which is used to refer the kinds of data that variables may hold in a programming language. In other words the general form of a class of data items is known as data type. The data type determines – how the data are represented are in memory and set of operations that are performed on this data. C provides some built in data types such as:
unsigned int, signed int, long int
float, double, long double
signed char, unsigned char
C automatically defines these built in data types for user. C also predefines the set of operations that are performed on these built in data types. For integer data type, we perform addition, subtraction, multiplication, division etc. Some data types can be defined by the user for its sake of convenience, such as structure, array etc.
Another concept regarding data is data object. Data object is a term used to represent a set of elements. For example there may be a set of natural numbers, a set of real numbers, a set of characters or a set of strings. A data object may be finite or infinite. And when we define some operations on data objects so that they can behave in a special way, we say it as a data structure. Therefore a data structure is defined as:
(i) a specific way of arranging data and
(ii) a set of operations performed on the data that make it behave in a certain way.
In other words you can say that a data structure is an aggregate of data objects. While designing a data structure one should not directly sit on the computer system and write his program directly on the computer system. Instead one should have the clear picture of its problem, its solution and what type of data should be received by user program and what type of result your program is expected to produce. Therefore for every data structure there are three different levels that must be followed by the programmer:
- Abstract (logical) level : On this level, the programmer has to decide how the elements ( data items ) are related to each other and what operations are needed. At this level, the programmer has no concern about the representation of the data in memory and how these operations are carried out. Therefore at this level it is necessary to understand your problem very carefully. For example, if you are at Delhi and want to go Goa then you must know the appropriate route to go Goa from Delhi, especially when there are more than one route. Similarly in programming environment, you must have clear idea to which one is used either a contiguous lists or a linked list when you deal with a number of data because some operations are easier for contiguous lists and other for linked lists.
- Implementation level : On the implementation level we do a specific way for representation of the data structure and it’s various operations in memory. It means that at implementation level we convert our algorithm into a computer program after deciding which one is the better way to implement it. Suppose you want to create a memory space for 100 numbers then it is the programmer who decides whether to allocate memory space either by using static memory allocation or dynamic memory allocation.
- Application Level : On this level we use the data structure which is implemented at earlier level. At this level we avail the facility provided by the various data structure. For example, stack is used to convert the postfix expression into infix expression and a queue is used to hold the processes that are waiting for different resources of the computer system in a multiprogramming operating system.
Primary and Secondary Data types
Data can be either primary data type or secondary data type. The data structure can contain any one of these data types.
Primary data type
The data types, which are not composed of other data types, are called as primary data type. C names primary data types as standard data type. Primary data types are integers, floats and characters data types. The primary data types could be of several types. For example an integer could be a short integer or a ling integer. Or a character could be an unsigned char or a signed char.
Secondary data type
The data types, which are composed of primary data types, are called as secondary data type. Normally these are defined by the programmer that’s why these are sometimes called user – defined data types. In C secondary data types are arrays, structures, pointers, unions, enum etc.
Data Structure Types
Generally there are two types of data structures:
- Built – in data structures
- User – defined data structures
Built – in Data Structures
These are those data structures, which are internally provided by the high – level languages, such as Pascal, Fortran, C, C++ etc. The programmer does not need to design these data structures. Built – in data structures are formed with the help of primary data types such as integers, floats, characters and Boolean. Some high – level languages (such as C, C++) does not provide Boolean data type.
Generally we have two types of Built – in data structures:
1. Array
2. Structure
Array
An array is basically a sequential group of components. In other words, you can say that it is basically a set of similar data types, such as a set of integers, a set of real numbers or a set of characters etc. Each component can be accessed by its relative position within the group; also each component of the array is a variable of the component type. To access a particular component we give the name of an array and an index that specifies which one of the component we want. For example, if we want to access the 5th component of array a [], we will use the notation a [4] because in C language the indexing starts from
0, 1, 2, 3, … n-2, n-2
for n number of components.
Structure
A structure is basically a collection of dissimilar data item. In other words a structure may have one or more integer field, one or more real field, one or more character field etc. the components of a structure are referenced by using a dot (.) operator. For example if an employee structure, Emprec, is defined as it’s following data fields:
Name
Age
Sex
Department
District
State
Pincode
Then individual components are referred as:
Emprec.Name
Emprec.Age
Emprec.Sex
Emprec.Department
Emprec.District
Emprec.State
Emprec.Pincode
User – defined Data Structure
The data structures, which are formed by the user for its sake of convenience, are referred as user – defined data structures. User – defined data structures are formed with the help of built – in data structures.
The user – defined data structures are classified into following two categories:
- Linear data structures
- Non – linear data structures
Linear data structures
The data structures whose components are processed sequentially, one by one, are referred as linear data structured. You can not process any element randomly. For example their processing are just like walking through staircase. If you want to move 5 steps up then you would have to start from step 1, then step 2, step3, and step 4 and in last at step 5. So it necessary to process 4 steps earlier.
Generally we have following types of linear data structures:
1. Stack
2. Queue
3. Linked list
Stack
A stack is a data structure in which insertions and deletions are made at the same end, top of the stack. Components are both inserted and removed from the beginning of the list. A stack is a “First – in Last – out” structure. The plate holder in a cafeteria has this property. We can take only the top plate. When we do this, the only below it rises to the top so that the next person can take one.
Queue
A queue is a data structure in which insertion and deletion are made at different end. Components are inserted at the rear of the list and removed from the front of the list. A queue is a “First – in First – out” structure. A waiting line in a bank or for a bus is suitable examples of a queue. There are two types of queues:
Linear queue
Circular queue
Linked List
A linked list is a dynamic data structure in which the components are logically ordered by their pointer fields rather than physically ordered as they are in array. The end of the list is indicated by the special pointer constant NULL. Each component of the linked list is called a node, having two fields – data fields and link field. The data field stores the information and the link field points to the next component.
Generally we have two types of list:
1. Singly linked list
2. Doubly linked list
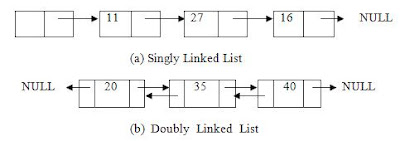
Figure 1
In singly linked list, we have one link field in a node that points to the next node, whereas in a doubly we have two link fields: one points to next node and one for the previous node.
Non – linear data structures
In non- – linear data structure, there is no rule, no order. Insertion and deletion can take place anywhere in the data structure. In other words the items of non- – linear data structure are not processed serially.
Non – linear data structure are of following types:
1. Tree
2. Graph
Tree
Tree is a non – linear data structure having hierarchical relationship between various components called nodes. Topmost node of a tree is called the root of the tree and remaining nodes are called leaves (children) of the tree as shown in figure 2.
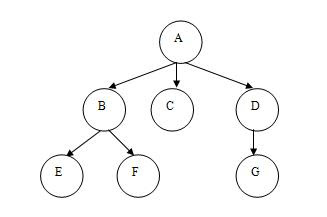
Figure 2
Graph
There is another non- – linear data structure, known as graph.
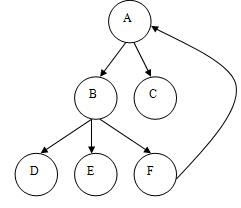
Figure 3
Data Structure Operations
There are six basic operations that are performed on data structures:
- Traversing
- Inserting
- Deleting
- Searching
- Sorting
- Merging
Traversing
By traversing we mean the processing of each data item in the data structure exactly once, from first element to last element.
Inserting
By inserting we mean an addition of a data item in the data structure at any position. For example an item can be inserted into an array either at first location; last location or at any specific location.
Deleting
By deleting an item, we mean deletion of a data item in a data structure from any location. For example in an array, we can delete first item; last item or item, which is at any specific location.
Sorting
By sorting we mean arranging of data items into ascending order or descending order, according to the requirements of the data structure.
Merging
By merging we mean combining of two same data structures into one data structure. For example if we have an array a [] of 10 elements and an array b [] of 15 elements then after merging of array a [] and array b [] into array c [], it would have 25 elements.
Searching
By searching we mean finding an item from a set of numbers.
Further I will Try to write more about data sructure. Till Than get knowledge from this article.