Biological functions of DNA
Biological functions include storage of DNA information (genes and genome), encoding proteins (transcription and translation) and its self-replication (DNA replication) to ensure the transmission of information to daughter cells during cell division.
Genes and Genome
The DNA can be considered as a store which reads the information (message) needed to build and sustain the body in which it resides, which is transmitted from generation to generation. The set of information that fulfills this function in a given organism is called the genome, and the DNA that constitutes, genomic DNA.
Genomic DNA (which is organized into chromatin, molecules that in turn are assembled into chromosomes) is found in the nucleus of eukaryotes, in addition to small amounts in mitochondria and chloroplasts. In prokaryotes, DNA is in an irregularly shaped body called the nucleoid.
The DNA coding

The genetic information of a genome is contained in genes, and the entire set of information corresponding to an organism is called its genotype. A gene is a unit of heredity and is a region of DNA that influences a particular characteristic of an organism (such as eye color, for example). Genes contain an "open reading frame (open reading frame) that can be transcribed as well as regulatory sequences such as promoters and enhancers, which control the transcription of the open reading frame.
From this point of view, the workers of this mechanism are protein. These can be structural, such as proteins of the muscles, cartilage, hair, etc.., Or functional, such as hemoglobin or the many enzymes in the body. The primary role of heredity is the specification of proteins, DNA being a sort of blueprint or recipe to produce them. Most of the time alteration of DNA cause protein dysfunction leading to the onset of illness. But in some cases, the changes may cause beneficial changes which give rise to individuals better adapted to their environment.
The approximately thirty thousand different proteins in the human body are made up of twenty different amino acids and a DNA molecule must specify the sequence in which these amino acids bind.
In the process of developing a protein, the DNA of a gene is read and transcribed into RNA. This RNA serves as messenger between DNA and the protein machinery that draw and therefore is called messenger RNA or mRNA. Messenger RNA serves as a template to the machinery that produces proteins to assemble the necessary amino acids in order to assemble the protein.
The central dogma of molecular biology established that the flow of activity and information era: DNA → RNA → protein. However, it has now been established that the "dogma" must be expanded, as they have found other information flows: in some organisms (virus RNA) information flow from RNA to DNA, a process known as transcription inverse or reverse ", also called" reverse transcription ". Furthermore, we know that there are DNA sequences that are transcribed into RNA and are functional as such, without actually ever translated protein: are the non-coding RNA, as is the case of interfering RNA.
The non-coding DNA (junk DNA)
The DNA genome of an organism can be divided conceptually into two: the one that codes for proteins (genes) and that does not code. In many species, only a small fraction of the genome encodes proteins. For example, only about 1.5% of the human genome consists of exons that encode proteins (20,000 to 25,000 genes), while over 90% consists of noncoding DNA.
Noncoding DNA (also called junk DNA, or junk DNA) corresponds to the genome sequences that do not produce a protein (from transpositions, duplications, translocations, and recombinations of viruses, etc..), Including introns. Until recently it was thought that non-coding DNA was not useless, but recent studies indicate that this is inaccurate. Among other functions, it is postulated that the so-called junk DNA regulates the differential expression of genes. For example, certain sequences have special affinity for proteins that have the ability to bind to DNA (such as homeodomains, receptor complexes of steroid hormones, etc..), with an important role in controlling the mechanisms of transcription and replication. These sequences are often called "regulatory sequences" and the researchers hypothesize that identified only a small fraction of those actually exist. The presence of both non-coding DNA in eukaryotic genomes and differences in genome size between species pose a mystery which is known as the "enigma of the value of C". Recently, a group of researchers from Yale University has discovered a non-coding DNA sequence to be responsible for that human beings have developed the ability to grasp and / or manipulate objects or tools.
Furthermore, some DNA sequences have a structural role in the chromosome, telomeres and centromeres contain little or no protein-coding gene, but are important for stabilizing the structure of chromosomes. Some genes do not encode proteins, but are transcribed into RNA: ribosomal RNA, transfer RNA and RNA interference (RNAi, RNA that are blocking the expression of specific genes). The structure of introns and exons of genes (such as immunoglobulins and protocadherinas) are important for allowing the alternative splicing of pre-messenger RNA that allow the synthesis of different proteins from the same gene (without this capability is not exist the immune system, for example). Some non-coding DNA sequences represent pseudogenes that have evolutionary value, allowing the creation of new genes with new functions. Other non-coding DNA duplication come from small regions of DNA, this is very useful, since the tracing these repetitive sequences allows studies on the human lineage.
Transcription and translation
In a gene, the sequence of nucleotides along a strand of DNA is transcribed into messenger RNA (mRNA) and this sequence in turn translates to a protein that an organism is capable of synthesizing or "express" in one or several times in their lives, using the information of that sequence.
The relationship between nucleotide sequence and the amino acid sequence of the protein is determined by the genetic code, which is used during the process of translation or protein synthesis. The coding unit of the genetic code is a group of three nucleotides (triplet), represented by the three initial letters of the nitrogenous bases (eg., ACT, CAG, TTT). The triplets of DNA bases are transcribed into messenger RNA complementary, and in this case the triplets are called codons (for the example above, UGA, GUC AAA). Each codon in the ribosome interacts with messenger RNA molecule of transfer RNA (tRNA or tRNA) containing the complementary triplet, called the anticodon. Each tRNA carries the amino acid corresponding to codon according to the genetic code, so that the ribosome is joining amino acids to form a new protein in accordance with the "instructions" from the mRNA sequence. There are 64 possible codons, therefore it is in more than one for each amino acid, some codons indicate the completion of synthesis, the end of the coding sequence, such termination codons or stop codons are UAA, UGA and UAG , nonsense codons or stop codons).
DNA Replication
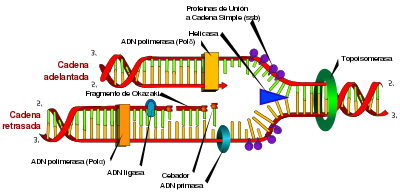
Schematic representative of DNA replication.
DNA replication is the process by which you obtain identical copies or replicas of a DNA molecule. Replication is essential for the transfer of genetic information from one generation to the next and, therefore, is the basis of heredity. The mechanism consists essentially in separating the two strands of the double helix, which serve as a template for subsequent synthesis of complementary strands to each of them. The end result is two molecules identical to the original. This type of replication is called semiconservative because each of the two molecules resulting from the duplication has a chain from the parent molecule and one newly synthesized.