If...else can also be nested inside other if...else constructs.
like we can put an if...else conditional construct inside another if...else also for further checking a different condition.
here's an example to check largest of 3 numbers.
/* Header Files included*/
//Also called preprocessor directives.
//iostrea.h to include basic input output functions i.e. cout() and cin().
/*conio.h header file to include getch() i.e. getcharacter function and clrscr() i.e. clrscr function.*/
#include
#include
//main starts here...
void main()
{
//to clear the screen.
clrscr();
// Three variables declared.
int a,b,c;
//Prompting the user to do some input.
cout<<"Enter 1st no"<
cout<<"Enter2nd no"<
cout<<"Enter 3rd no"<
//Check if 1st no is greater than b.
if(a>b)
{
//checking if 1st no is also greater than c.
if(a>c)
{
//Coz 1st no is greater than 2nd and also than 3rd.
cout<<"1st no is largest"<
else
{
//Coz 3rd no is greater than 2nd and also than 1st.
cout<<"3rd no is largest"<
}
else
{
//checking if 2nd no is also greater than 3rd.
if(b>c)
{
cout<<"2nd no is largest";
}
//Because 3rd no is largest then print it.
else
{
cout<<"3rd no is largest";
}
}
getch();
}
Note: Lines with leading with double slashes (//) and single slash with a star symbol(/*..........*/) are comments. These lines will not be compiled by the compiler and are ignored.
In if...else construct we can check for many conditions with
else if(condition) after an if(statement) expression. Like,
We want to check the value for a variable we can check like that...
int X=90;
if(X>0)
{
cout<<"X exceeds Zero"<
else if(X==0)
{
cout<<"X equals Zero"<
else if(X==10)
{
cout<<"X equals ten"<
else
{
cout<<"X exceeds ten"<
As you can see from the above code, We can check the value for a variable using if... if else... else... construct.
But the statements became quite complex as with using many if and else if conditions.
The above statements can also be simplified by using Switch...Case construct.
Switch...case construct:
-----------------------------
This is used when there are multiple values for a variable. When it gets executed the condition variable is evaluated and compared with each case constant and the execution is transferred to the respective case block. and if no matching case block is found the execution is transferred to the default block.
SYNTAX:
switch(variable_name)
{
case constant_expression1:
statements;
break;
case constant_expression2:
statements;
break;
case constant_expression3:
statements;
break;
case constant_expression4:
statements;
break;
default:
statements;
}
The keyword switch is followed by the variable in parentheses, as show below:
switch(X),
Each case keyword is followed by a case constant, in simple terms, we can say the condition.
case 1:
The datatype of the case constant should match with the datatype of the variable.
int this time.
The break keyword is used to skip the execution of the remaining statements after a condition is met.
The default keyword is used to execute the statements if non of the case constant matches the condition.
Switch...Case continued.
As i told we use switch...case construct when we've multiple values for a variable.
So we can check the values for a variable using switch case. For eg.
int X=20;
switch(X)
{
case 0:
cout<<"X is Zero"<
case 10:
cout<<"X is Ten"<
case 20:
cout<<"X is Twenty"<
default:
cout<<"X is not Zero or Ten nor Twenty"<
By executing the above statements, The condition is evaluated with each case expression. if any matching case found, the statements executes of that case otherwise the sequence of execution is transferred to the next case block. If non of the matching case block found, the default block executes.
There are many kinds of loops in C++.
So let's start with the While loop first.
While Loop:
---------------
The while loop is used to execute a statement or block of statements as long as a specified condition is true. The general form of the while loop is:
while(condition)
{
loop_statement;
}
Here loop_statement is executed repeatedly as long as the condition expression has the value true. After the condition becomes false, the program continues with the statement following the loop. As always, a block of statements between braces could replace the single loop_statement.
You could write some statements to print numbers from 1 to 10. Like
int X=1;
while(X<11)
{
cout<
}
The above loop statements will print numbers starting from 1 to 10.
Here's the explaination, how the above statements will be executed:
Initially X is having a value "1". The while loop will check the value of X if it is less than 11. If so the execution flow will enter the body of the loop and print the value of X i.e. 1 this time. Then X will be incremented by 1. Now X is having a value 2 which is again less than 11 so it'll again print the value of X i.e. 2 this time. So it'll print the value of X till it's value is 10. After this X will increment by 1 which will make X equals to 11. Now, when the condition is checked the value of X is not less than 11. So the loop will be discarded and the execution will continue with the statements following the loop.
Another kind of loop in C++ is do while loop.
Do... While loop:
--------------------
The do-while loop is similar to the while loop in that the loop continues as long as the specified loop condition remains true. The main difference is that the condition is checked at the end of the loop which contrasts with the while loop and the for loop where the condition is checked at the beginning of the loop. Consequently, the do-while loop statement is always executed at least once. The general form of the do-while loop is:
do
{
loop_statements;
}
while(condition);
You could replace the while loop in the last version of the program to print numbers from 0 to 10 with a do-while loop:
int X=1;
do
{
cout<
while(X<11);
BINARY TREE
Binary tree is a set of finite nodes which is either empty or consists of one or more nodes in which each node has at most two disjoint binary subtrees called left subtree or right subtree respectively. Thus we can say that there may be a zero degree node or a one degree node or a two degree node.
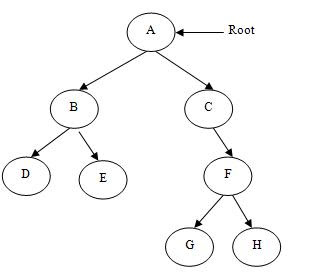
Figure-(a) shows a typical binary tree.
In figure-(a) A is the root node, B and C are the left subtree and right subtree of root node A respectively. This binary tree is not a strictly binary tree. A binary tree is strictly binary tree if every non-terminal node has two subtrees or you can say if every non-terminal node consists of non-empty left subtree as well as non-empty right subtree.
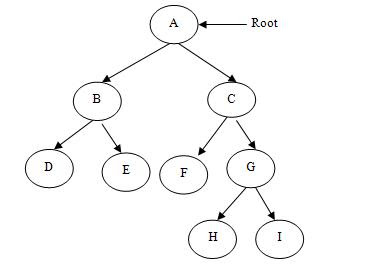
Figure-(b) shows a strictly binary tree.
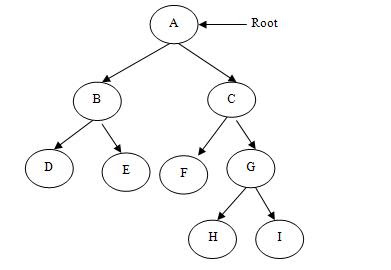
Figure (c)
The binary trees that we have discussed so far are not complete binary trees. A complete binary tree is as shown in figure-(c). Thus in complete binary tree if there are ‘n’ number of nodes at level ‘m’ then it contains at most ‘2n’ nodes at level ‘m+1’.
Implementation of Binary Trees
Binary trees are implemented in two ways:
- Array implementation of Binary Trees
- Linked List implementation of Binary Trees
Array implementation of Binary Trees
In an array implementation of binary trees we use one-dimensional array. The nodes stored in an array are accessible sequentially. Consider the complete binary tree. and number the nodes beginning with the root from left to right at each level. The root node is numbered 0, then the left child as 1 and right child as 2 and so on.
Now if we place node number at index 0 then in successive positions the left child and right child are stored. Figure-(d) representation of this binary tree.
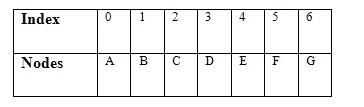
Figure (d)
This table concludes that if father is at index ‘n’ then its left children will be at index 2n+1 and its right children will be at index 2n+2. Let we want to find out the left and right child position of node C. Since the node C is placed at index 2, therefore its left child would be at index 5 (2*2+1) and its right child would be at index 6 (2*2+2).
The situation is pleasant so far because it is complete binary tree. But if the binary tree is not complete then it definitely results in unnecessary wastage of memory space because array is static in nature. For example let we have a binary tree as shown in figure- (e).
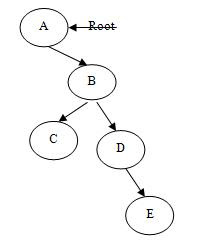
figure (e)

The array representation of this binary tree is as shown in figure- (f)
From this table it is clear that if a tree is far from its complete behavior then the array implementation would waste a lot of memory space. This type of problem is overcome by implementing the binary tree in linked list.
Linked List implementation of Binary Trees
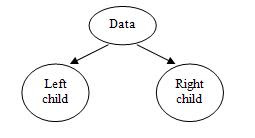
In this we will use a linked list in which elements are treated as nodes. Each node a binary tree has three fields, as follows:
- Left child
- Data
- Right child
The data field contains the value of the node, the left child contains the information about the left child and right child contains the information about the right child. Figure-(g) shows this.

The structure of a binary node is defined as:
struct treenode{
struct treenode *lchild;
int data;
struct treenode *rchild;
};
typedef struct treenode BTNode;
Figure-(h) shows the linked list representation of a binary tree shown in figure-(e)
Firgure (h)
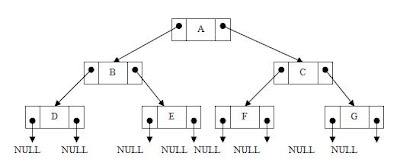
From the figure it is clear that the left link field and right link field of leaf nodes contains a NULL value each. However if a parent node has empty left child then its left link field would be set to NULL and if it has empty right child then its right link field is set to NULL.
Binary Trees Traversals
Traversal of a binary tree is one of the most important operations required to be done on a binary tree. Traversing of a binary tree is a process of visiting every node in the tree exactly once. Thus it is necessary to visit the nodes of a tree in some linear fashion. There are so many ways in which a binary tree is traversed, but we will consider those techniques in which the left subtree is traversed before the right subtree, such as first visit the node, then traverse left subtree, and finally traverse the right subtree. In such situations where the left subtree is traversed before the right subtree, there are three possible traversal techniques: Inorder, Preorder and Postorder.
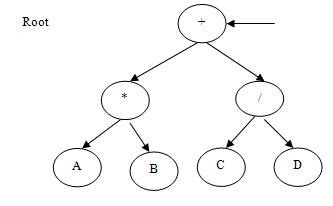
Figure (a)
Inorder Traversal
In this, if there is a binary tree ‘T’ then the left subtree of ‘T’ is traversed first, then the root node of ‘T’ is visited and then the right subtree of ‘T’ traversed. Since the left subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the left subtree. Similalrly the right subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the right subtree also. Each node of a binary tree is of type BNode and it contains a character as its information.
Here is the function that implements this task.
Inorder(TNode *rt){
if (rt != NULL)
{
Inorder(rt->lchild);
printf("%c\t", rt->data);
Inorder(rt->rchild);
}
}
If this function is applied on the tree shown in figure-12.38 then the following output would be produced:
A * B + C / D
Preorder Traversal
In this, if there is a binary tree ‘T’ then the root node of ‘T’ is visited, then the left subtree of ‘T’ is traversed first, and then finally the right subtree of ‘T’ traversed. Since the left subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the left subtree. Similalrly the right subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the right subtree also.
Here is the function that implements this task.
Preorder(TNode *rt){
if (rt != NULL)
{
printf("%c\t", rt->data);
Preorder(rt->lchild);
Preorder(rt->rchild);
}
}
If this function is applied on the tree shown in figure-38 then the following output would be produced:
+ * A B / C D
Postorder Traversal
In this, if there is a binary tree ‘T’ then the right subtree of ‘T’ traversed first, then the left subtree of ‘T’ is traversed first, and then finally then the root node of ‘T’ is visited. Since the left subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the left subtree. Similarly the right subtree of a binary tree can be itself a binary tree therefore the same procedure is applied to the right subtree also.
Here is the function that implements this task.
Postorder(TNode *rt){
if (rt != NULL)
{
Postorder(rt->lchild);
Postorder(rt->rchild);
printf("%c\t", rt->data);
}
}
If this function is applied on the tree shown in figure-38 then the following output would be produced:
A B * C D / +
Introduction
As a programmer you will develop solutions to problems, solutions that transform given data (input) into required results (output). Generally this data is placed in secondary memory. Since the processor can only process the data that is available in main memory, so this data (from secondary memory) has to be transferred to the main memory first). Finally when the final result is produced it is to be preserved for the future use by transferring it from main memory to secondary memory.
It is the programmer who tells the computer what to do. As problem solvers, we use the computer to implement our solutions. These solutions are implemented on a computer using any programming language, such as Pascal, C or C++. A programming language reflects the range of operations a computer can perform. In this chapter we will study some of the strategies we can use to solve problems. Finally we will study about different data structures which are used to organize data in memory and typical operations that can be performed on these data structures.
The Concept of Programming
Have you ever noticed that your behavior and your thoughts are characterized by logical sequences. Every step of your life has a certain order to it. No doubt, a lot of what you do everyday is done automatically, on an unconscious level since it is not necessary for you to consciously think of every step involved in a process as simple as you brush your teeth. If you try to do this at conscious level then it involves all the following actions in a certain order or sequence as follows:
- take a brush
- clean it with water
- put some toothpaste on it
- rub the brush against your teeth for a minute
- take a glass of water and clean your teeth
Initially you had to learn this. But after some time, the action is completely automatic. In other words much of what you do unconsciously you once had to learn. After all every music requires a definite a sequence of notes in order to be recognizable.
The ultimate conclusion is that whatever we do at conscious level or at unconscious level, it takes place in a prescribed order. This ordering is called programming and when this programming is done on a computer language it is called computer programming. On the similar track, a computer program is a sequence of instructions that must be understood by the computer.
The programming process is basically a two step process:
- A problem solving phase
- An implementation phase
Problem Solving Phase
In problem solving phase, we firstly understand (define) the problem or you can say what a problem is. After knowing the problem, we develop a logical sequence of steps to be used to solve this problem because the computer can not itself analyze the problem and come up with a solution. It is the user or you can say a programmer who must arrive at a solution and communicate it to the computer. Thus the programmer begins the programming process by analyzing the problem and developing a general solution called an algorithm. An algorithm is just a step-by-step procedure for solving a problem in a finite amount of time for all possible conditions or you can say an algorithm is simply a verbal or written description of a logical sequence of actions.
After developing a general solution, the programmer “walk through” the algorithm by following logical sequences step by step mentally or manually. If programmer finds that this testing of the algorithm does not produce satisfactory result, he/she repeats the problem-solving phase, understand the problem again and coming up with another algorithm. Of course there may be more than one solution to a problem, it is the programmer who selects which is the best one.
An Implementation Phase
Once the solution is selected, it is programmer’s duty to translate this algorithm into a programming language. Translating an algorithm into a programming language is called coding the algorithm. For this we use ‘C’ programming language in this book. Like any simple language, a programming language is a set of rules, symbols, and special words used to construct a program. A programming language is essentially a simplified form of English (with math symbols) that adheres to a strict set of grammar rules.
After coding the algorithm, the resulting program is tested by executing (running) it on the computer system. If the program produces correct result then it is OK; otherwise the programmer must determine what is wrong and modify the algorithm and program as needed. If the program produces the desired results then it is used in practical application. The combination of coding and testing an algorithm is often referred to as implementing an algorithm.
Figure (a) shows the relationship between a problem solving phase and an implementation phase.
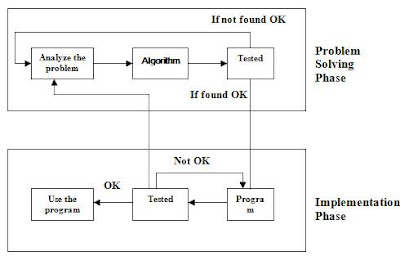
Figure (a)
Here one should not confuse with the definition of a program and an algorithm. An algorithm is just a way of expressing the solution. It may be in a programming language or in English. And when an algorithm is expressed in a programming language it is called a program. Another main point to note is that you should not try to take a short cut in the programming process by going directly from the problem definition to the coding of the program as shown in figure (b)
Of course it saves a lot of time, but if the program does not produce the desired result in first chance then you will spend a lot of extra time in correcting errors (debugging) and revising an ill-conceived program. Therefore the best strategy is to go to problem solving phase first and then implementation phase.

Figure (b)
Introduction
A data structure is the logical or mathematical model of a particular organization of data. Thus a data structure is defined by
(i) organizing data in a specific way
(ii) defining a set of operations performed on the data that make it behave in a certain way
Data structure is a way of organizing all data items that considers not only the data items are stored but also their relationship to each other. Data structures are of two types: linear data structures and non-linear data structures. In linear data structures the elements are processed in a linear sequence, that is one by one. But in non-linear data structures elements are processed randomly. Stacks, queues and lists are examples of linear data structures whereas trees and graphs are examples of non-linear data structures. In this chapter we will study about implementation of typical data structures like lists, stacks, queues and trees.
Lists
Lists are collection of items in which each element contains data items as well as information about other elements of the list. There are two types of lists – one way lists and two-way lists. In one-way lists traversing is made in one direction only whereas in two-way lists traversing is made in either direction or both directions.
Stacks
Stack is one of the most useful linear data structure – Stack in which elements are inserted and deleted at one end called as top of the stack.
Queues
After this we will study another non-linear data structure – Queues. The concept of a ‘queue’ data structure is similar to its ordinary meaning, that is a line of people waiting to purchase something, where the first person in the line is the first person to be served. In queue, the elements are inserted at one end called rear end of the queue and deleted at other end of the queue called front end of the queue.
Trees
Trees are one of the most useful non-linear data structures. In trees we will see the implementation of binary search tree – a special type of binary tree.
Implementation of Data Structures
Now let us see implementation of these data structures in C.
Example-1 Write a program that implements a singly linked list
/* A singly linked list is a collection of nodes in which traversing is done in one direction only. In this we take a node consisting of two fields – data field and link field. The data field consists of information and link field contains the address of next node. In case of last node, the link field contains a Null. */
/* Program – lohit.c */
#include
#include
#include
struct node
{
int data;
struct node *link;
};
typedef struct node Node;
main()
{
Node *first;
int choice, item, pos;
(Node *) getnode();
InitializeList(&first);
clrscr();
printf("\nCreating a Singly Linked List.\n");
CreateList(&first);
while (1)
{
printf("\n\n\tImplementation ofa Singly Linked List.\n");
printf("\n\t\t1. Insertion as a First Node.");
printf("\n\t\t2. Insertion as a Last Node.");
printf("\n\t\t3. Insertion of a Node at any specific location.");
printf("\n\t\t4. Deletion of First Node.");
printf("\n\t\t5. Deletion of Last Node.");
printf("\n\t\t6. Deletion of any Node.");
printf("\n\t\t7. Display");
printf("\n\t\t0. Exit");
printf("\n\n\tEnter (1/2/3/4/5/6/0) - ");
scanf("%d",&choice);
switch (choice)
{
case 1:
printf("\nEnter the item of information = ");
scanf("%d",&item);
InsertFirst(&first,item);
break;
case 2:
printf("\nEnter the item of information = ");
scanf("%d",&item);
InsertLast(&first,item);
break;
case 3:
printf("\nEnter the item of information = ");
scanf("%d",&item);
printf("\nEnter the node number where you want to insert the item = ");
scanf("%d",&pos);
InsertAtAny(&first,item,pos);
break;
case 4:
DeleteFirst(&first);
break;
case 5:
DeleteLast(&first);
break;
case 6:
printf("\nEnter the node number you want to delete = ");
scanf("%d",&pos);
DeleteAny(&first,pos);
break;
case 7:
Traversing(first);
break;
case 0:
exit(0);
}
}
}
InitializeList(Node **first)
{
(*first)=NULL;
}
CreateList(Node **first)
{
Node *temp, *current;
int item;
printf("\nEnter the item of information (-9999 to terminate) = ");
scanf("%d",&item);
while (item != -9999)
{
temp = getnode();
temp->data = item;
temp->link = NULL;
if ((*first) == NULL)
(*first) = temp;
else
current->link = temp;
current = temp;
printf("Enter the item of information (-9999 to terminate) = ");
scanf("%d",&item);
}
}
Traversing(Node *first)
{
if (first == NULL)
{
printf("\nList is empty. Press any key to Continue....");
getch();
return;
}
printf("\nContents of a linked list are as….\n");
printf("\nStart -->");
while (first != NULL)
{
printf("%d-->",first->data);
first=first->link;
}
printf("End");
getch();
}
InsertFirst(Node **first, int item)
{
Node *temp;
temp=getnode();
if (temp==NULL)
{
printf("\nUnable to create a new node. Press any key to Continuee....");
getch();
return;
}
temp->data=item;
temp->link=(*first);
(*first)=temp;
}
InsertLast(Node **first, int item)
{
Node *temp, *current;
temp=getnode();
if (temp==NULL)
{
printf("\nUnable to create a new node. Press any key to Continuee....");
getch();
return;
}
temp->data=item;
temp->link=NULL;
if (*first==NULL)
(*first)=temp;
else
{
current=(*first);
while (current->link!=NULL)
current=current->link;
current->link=temp;
}
}
InsertAtAny(Node **first, int item, int pos)
{
Node *current, *previous, *temp;
int i=1;
temp=getnode();
if (temp==NULL)
{
printf("\nUnable to create a new node. Press any key to Continuee....");
getch();
return;
}
if ((*first==NULL)||(pos==1))
{
temp->data=item;
temp->link=NULL;
(*first)=temp;
return;
}
current=(*first)->link;
previous=(*first);
while (current!=NULL)
{
if ((i+1) == pos)
break;
else
{
previous=current;
current = current->link;
i++;
}
}
temp->data = item;
temp->link = current;
previous->link = temp;
}
DeleteFirst(Node **first)
{
Node *temp;
int item;
if (*first == NULL)
{
printf("\nList is empty. Press any key to Continue....");
getch();
return;
}
temp=(*first);
item = temp->data;
(*first) = (*first)->link;
freenode(temp);
printf("\nDeleted item = %d",item);
getch();
}
DeleteLast(Node **first)
{
Node *current, *previous;
int item;
if (*first == NULL)
{
printf("\nList is empty. Press any key to Continue....");
getch();
return;
}
current = (*first);
if ((*first)->link == NULL)
(*first) = (*first)->link;
else
{
while (current->link != NULL)
{
previous=current;
current=current->link;
}
previous->link=current->link;
}
item = current->data;
freenode(current);
printf("\nDeleted item = %d",item);
getch();
}
DeleteAny(Node **first, int pos)
{
Node *current, *previous;
int item, i=2;
if (*first == NULL)
{
printf("\nList is empty. Press any key to Continue....");
getch();
return;
}
if (pos == 1)
{
current = (*first);
item=current->data;
(*first) = (*first)->link;
freenode(current);
printf("\nDeleted item = %d",item);
return;
}
current = (*first)->link;
previous=(*first);
while (current)
{
if ( i == pos)
{
previous->link = current->link;
item = current->data;
freenode(current);
printf("\nDeleted item = %d",item);
getch();
return;
}
else
{
previous = current;
current = current->link;
}
i++;
}
}
getnode()
{
Node *t;
t = (Node *)malloc(sizeof(Node));
return t;
}
freenode(Node *t)
{
free(t);
}
Here is the output of this program….
Creating a Singly Linked List.
Enter the item of information (-9999 to terminate) = 11
Enter the item of information (-9999 to terminate) = 42
Enter the item of information (-9999 to terminate) = 35
Enter the item of information (-9999 to terminate) = 87
Enter the item of information (-9999 to terminate) = 45
Enter the item of information (-9999 to terminate) = -9999
Implementation ofa Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 3
Enter the item of information = 55
Enter the node number where you want to insert the item = 4
Implementation of a Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 7
Contents of a linked list are as….
Start -->11-->42-->35-->55-->87-->45-->End
Implementation of a Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 4
Deleted item = 11
Implementation of a Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 6
Enter the node number you want to delete = 5
Deleted item = 45
Implementation of a Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 7
Contents of a linked list are as….
Start -->42-->35-->55-->87-->End
Implementation ofa Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) – 2
Enter the item of information = 88
Implementation of a Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 7
Contents of a linked list are as….
Start -->42-->35-->55-->87-->88-->End
Implementation ofa Singly Linked List.
1. Insertion as a First Node.
2. Insertion as a Last Node.
3. Insertion of a Node at any specific location.
4. Deletion of First Node.
5. Deletion of Last Node.
6. Deletion of any Node.
7. Display
0. Exit
Enter (1/2/3/4/5/6/0) - 0
I Hope You will Get Little Bit Knowledge From This...
More Articles …
Page 15 of 21